One of the much neglected considerations, when sizing applications for virtualization, is the impact of Non-Uniform Memory Access (NUMA).
What is (NUMA)?
Non-Uniform Memory Access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to a processor. Under NUMA, a processor can access its own local memory faster than non-local memory, that is, memory local to another processor or memory shared between processors. Intel processors, beginning with Nehalem, utilize the NUMA architecture. In this architecture, a server is divided into NUMA nodes, which comprises of a single processor and its cores, along with its locally connected memory. For example, a B200 M3 blade with 3.3 GHz processors and 128 GB of RAM would have 2 NUMA nodes; each node having 1 physical CPU with 4 cores and 64 GB of RAM.
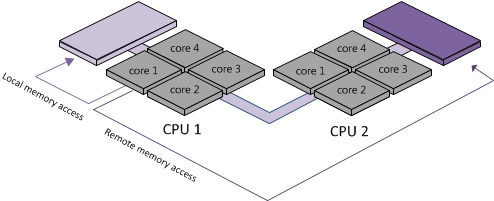
Memory access is designed to be faster when is it localized within a NUMA node compared to remote memory access since the memory access exchange would have to traverse the interconnect between 2 NUMA nodes. As a result, it is preferable to keep remote memory access to a minimum when sizing VMs.
How Does NUMA Affect VM Sizing?
vSphere is NUMA aware and when it detects that it is running on a NUMA system, such as UCS, the NUMA CPU Scheduler will kick in and assign a VM to a NUMA node as a NUMA client. If a VM has multiple vCPUs, the Scheduler will attempt to assign all the vCPUs for that VM to the same NUMA node to maintain memory locality. Best practices dictate that a the total quantity of vCPUs and vRAM for a VM should ideally not exceed the number of cores in the physical processor or the amount of RAM of its assigned NUMA node. For example, a 4-way VM on a B200 M3 with 4 or 8 core processors and 128 GB RAM will reside on a single NUMA node, assuming it has no more than 64 GB of vRAM assigned to it.
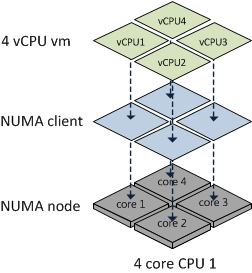
However, if the vCPU count of a VM exceeds the number of cores in its ESXi server’s given NUMA node or the vRAM exceeds the physical RAM of that node, then that VM will NOT be treated as a normal NUMA client.
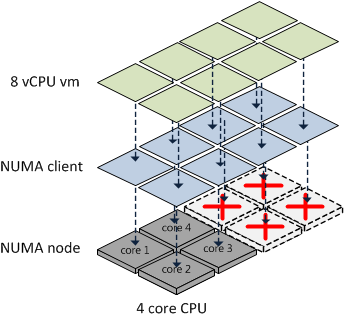
Prior to vSphere 4.1, the ESXi CPU Scheduler would load balance the vCPUs and vRAM for such a VM across all available cores in a round-robin fashion. This is illustrated below.
As you can see, this scenario increase the likelihood that memory access will have to cross NUMA node boundaries, adding latency to the system.
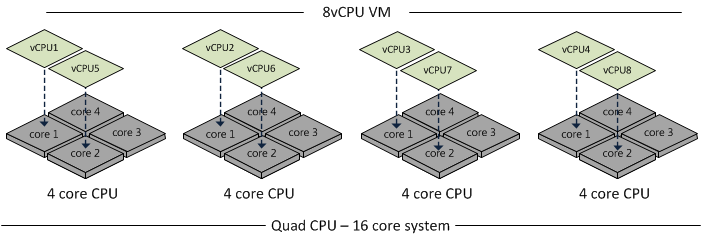
Beginning with 4.1, vSphere supports the concept of a Wide-VM. The ESXi CPU Scheduler now splits the VM into multiple NUMA clients so that better memory locality can be maintained. At VM power-up, the Scheduler calculates the number of NUMA clients required so that each client can reside in a NUMA node. For example, if an 8-way 96 GB VM resided on a B200 M3 with 4-core processors and 128 GB RAM, the Scheduler will create 2 NUMA Clients, each assigned to a NUMA node.
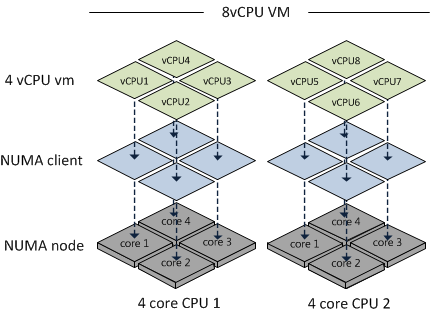
The advantage here is that memory locality is increased, which potentially decreases the amount of high latency remote memory access. However, it does not provide as much performance as a VM which resides on a single NUMA node. Btw, if you create a VM with 6 vCPUs on a 4-core B200 M3, the Scheduler will create 2 NUMA nodes – one with 4 cores and the other with 2 cores. This is due to the fact that the Scheduler attempts to keep as many vCPUs in the same NUMA node as possible.
vNUMA
Beginning in vSphere 5.0, VMware introduced support for exposing virtual NUMA topology to guest operating systems, which can improve performance by facilitating guest operating system and application NUMA optimizations.
Virtual NUMA topology is available to hardware version 8 and hardware version 9 virtual machines and is enabled by default when the number of virtual CPUs is greater than eight. You can also manually influence virtual NUMA topology using advanced configuration options.
You can affect the virtual NUMA topology with two settings in the vSphere Client: number of virtual sockets and number of cores per socket for a virtual machine. If the number of cores per socket (cpuid.coresPerSocket) is greater than one, and the number of virtual cores in the virtual machine is greater than 8, the virtual NUMA node size matches the virtual socket size. If the number of cores per socket is less than or equal to one, virtual NUMA nodes are created to match the topology of the first physical host where the virtual machine is powered on.
Recommendations
While the ability to create Wide-VMs do alleviate the issues of memory access latency by reducing the number of memory requests that will likely need to traverse NUMA nodes, there is still a performance impact that could affect Business-Critical Applications (BCA) with stringent performance requirements. For this reason, the following recommendations should be considered when sizing BCAs:
- When possible, create smaller VMs, instead of “Monster” VMs, that fit into a single NUMA node. For example, design VMs with no more than 4 vCPUs and 64 GB of RAM when using a B200 M3 with 4-core processors and 128 GB of RAM.
- When feasible, select blade configurations with NUMA nodes that match or exceed the largest VMs that will be hosted. For example, if a customer will be creating VMs with 8 vCPUs, consider choosing a blade with 8 or 10 cores, assuming the CPU cycles are adequate.
- If a “monster” VM, such as a 32-way host, is required, it may advantageous to select blades with higher core density so that larger NUMA nodes can be created and memory locality can be increased.
Conclusion
Customers should distribute their virtual machine workloads across multiple smaller VMs and to keep their VMs within NUMA node boundaries.
For more information about virtualizing Business Critical Applications, go to VMware’s Virtualizing Business Critical Enterprise Applications webpage and read all available documentation, including the “Virtualizing Business Critical Applications on vSphere” white paper.
No comments:
Post a Comment